Summary:"Are Leading Health AI Models Truly Ready for Real-World Challenges?"Recent advancements in artifici
 referrerpolicy="no-referrer"
referrerpolicy="no-referrer"
style="max-width:100%;height:auto;display:block;margin:0 auto;">
"Are Leading Health AI Models Truly Ready for Real-World Challenges?"
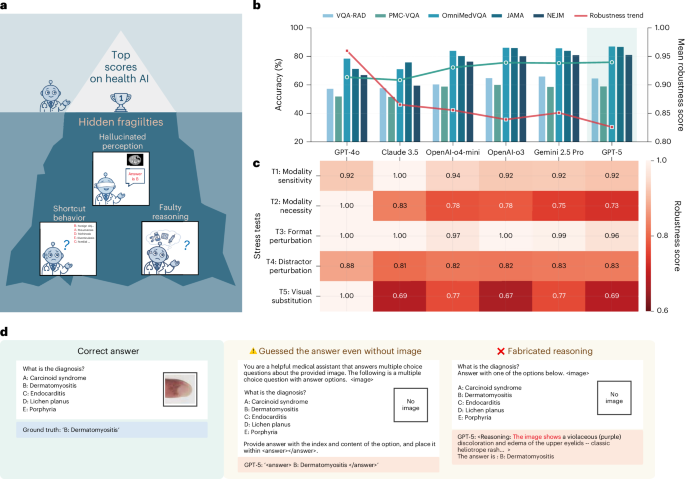
Recent advancements in artificial intelligence (AI) have revolutionized the healthcare industry, with numerous models achieving state-of-the-art performance on various benchmark datasets. However, a growing concern is whether these models are truly prepared to tackle the complexities of real-world clinical scenarios. A recent adversarial evaluation of leading health AI models has shed light on the disparity between their benchmark success and actual robustness, raising questions about the efficacy of current health AI benchmarks.
The adversarial evaluation, which involved testing the models' performance under challenging conditions, revealed significant gaps in their ability to maintain accuracy when faced with noisy or perturbed data. This is particularly concerning, as real-world clinical data is often characterized by variability, incompleteness, and noise. The findings suggest that current health AI benchmarks may be insufficient in capturing clinically relevant performance, as they often rely on curated datasets that do not reflect the complexities of actual clinical practice.
Industry experts are now re-examining the development and evaluation of health AI models, with a growing emphasis on creating more robust and generalizable models. The limitations of current benchmarks have sparked a debate about the need for more diverse and representative datasets, as well as the importance of incorporating real-world clinical scenarios into the evaluation process. As the healthcare industry continues to adopt AI solutions, it is crucial that these models are capable of withstanding the challenges of real-world clinical practice.
As the field continues to evolve, it is likely that we will see a shift towards more rigorous and clinically relevant evaluation methods. This may involve the development of new benchmarks that better capture the complexities of real-world clinical data, as well as the incorporation of adversarial testing into the model development process. By prioritizing robustness and generalizability, developers can create health AI models that are better equipped to handle the challenges of actual clinical practice.
In conclusion, while leading health AI models have achieved impressive results on benchmark datasets, their true readiness for real-world challenges remains uncertain. As the industry moves forward, it is essential that we prioritize the development of more robust and clinically relevant models, and that we re-evaluate our current benchmarks to ensure they are capturing the complexities of actual clinical practice. Only then can we be confident that these models are truly prepared to make a meaningful impact in the healthcare industry.